¶ DBT Project Initialization
This page allows you to create a new dbt-core Project and store it in a new branch in just a few clicks. The branch will include the settings you've selected.
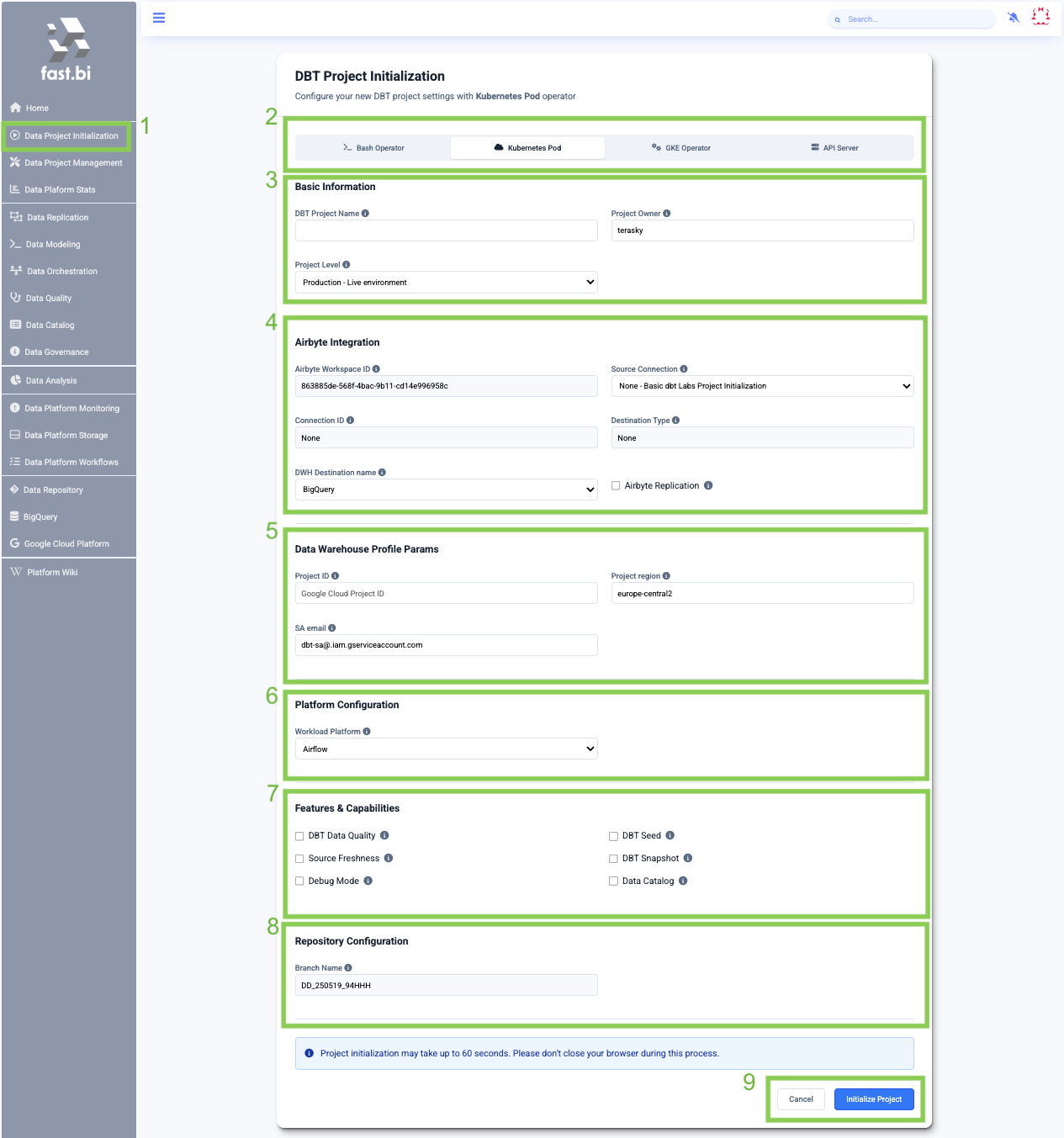
- In the menu on the left, you can select “Data Project Initialization.”
- You need to select the run operator that will be used to execute the models
- Bash Operator – utilizes Airflow server resources and is best suited for small DBT projects, which deliver fast results.
- Kubernetes Pod Operator – creates a separate Kubernetes pod for each DBT task, well-suited for nightly data transformation jobs.
- GKE operator - will create a Google Cloud Kubernetes Cluster with powerful resources. Most suitable for long-running external data transformation (cloud-to-cloud).
- API Server Operator - will create a dedicated dbt project API Server for accepting dbt commands for running data transformations, well-suited for ent. level requirements.
- Basic Information: Set of required fields for the dbt project:
- DBT Project name — The alphanumeric name assigned to your new dbt project
- Project Owner – A DBT Project Owner manages the development and maintenance of a DBT project, ensuring data quality, best practices, and alignment with organisational data goals
- Project level – The environment or fabric in which the dataset belongs: this is an additional qualifier available on the identifier, to allow disambiguating datasets that live in Production environments from datasets that live in Non-production environments, such as Staging, QA, etc. Default as "Production".
- Airbyte Integration: Most projects start with data replication
- Airbyte Workspace ID – The identifier for the Airbyte workspace where the data integration pipelines are managed. Based on fast.bi environment.
- Source connection – The name assigned to the source connection within Airbyte, providing a human-readable label for the connection associated with the DBT project.
- Connection ID – Connection ID within Airbyte, associated with the chosen source connection.
- Destination type – 1 - Denormalized Airbyte source tables, 2 - Normalized Airbyte source tables.
- DWH Destination name – Name of the destination data warehouse (e.g., BigQuery, Snowflake).
- Airbyte Replication – A boolean value indicating is to create an Airbyte group of tasks Airflow DAG. Features are enabled (True) or not (False). Orchestrate data replication through the data orchestration module.
- Data Warehouse Profile Params:
- BigQuery:
- Project ID – The unique identifier associated with your Google Cloud Project, particularly relevant for BigQuery Data Warehouse
- Project region – The geographic location where your Google Cloud (BigQuery) resources are hosted, like europe-central2 or us-central1
- SA email – The Service Account email used to authenticate and authorize access to Google Cloud resources (example: dbt-sa@your-project-id.iam.gserviceaccount.com).
- Snowflake:
- Database – The database name where your data will be stored or queried from.
- Schema – A logical grouping of tables within a database. Helps organize your data into different namespaces.
- Warehouse – The compute resource that runs your SQL queries. Warehouses scale separately from the data storage
- Role – The permission set assigned to a user or service account that defines what actions they are allowed to perform in the database or cloud environment.
- BigQuery:
- Platform Configuration
- Workload Platform – Specifies the platform used to manage workloads.
- Features & Capabilities
- DBT Data Quality – A boolean value indicating whether dbt data quality (Re_Date package) features are enabled (True) or not (False)
- DBT Seed – A boolean value indicating whether dbt seed functionality is enabled (True) or not (False)
- Source Freshness – A boolean value indicating whether the source dataset and source freshness verification are enabled (True) or not (False)
- DBT Snapshot – A boolean value indicating whether dbt snapshot functionality is enabled (True) or not (False)
- Debug Mode – A boolean value indicating whether dbt snapshot functionality is enabled (True) or not (False)
- Data Catalog – A boolean value indicating whether data governance (DataHub) features are enabled (True) or not (False)
- Basic BI Data-Model – A boolean value indicating whether data visualization (BI) features are enabled (True) or not (False)
- Repository Configuration
- Branch name – The automatically generated branch name for the data model repository
- Initialize Project – a button that submits the form and sets up the DBT project.
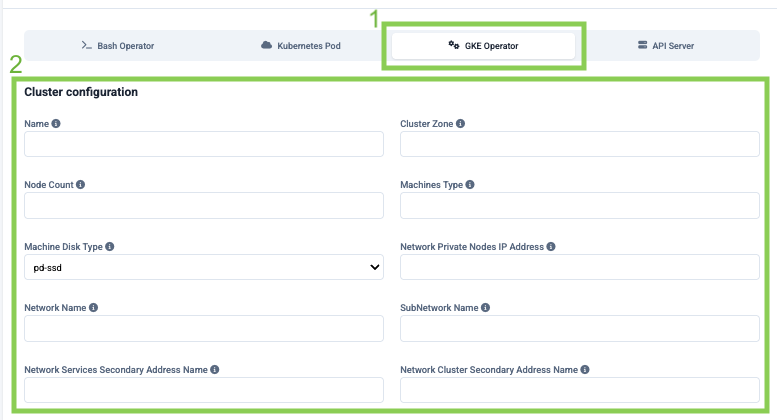
¶ For the GKE operator, there is one more section to configure
- GKE operator
- Cluster configuration:
- Name – The unique name assigned to the Kubernetes cluster for your DBT project, specifically the Google Kubernetes Engine (GKE) service cluster name.
- Cluster Zone – The geographical zone where the Kubernetes cluster is located, specifically the GKE service cluster zone.
- Node count – The number of nodes allocated for the Kubernetes cluster, indicating the GKE service cluster node count.
- Machines type – The type or configuration of machines used for the nodes in the Kubernetes cluster, denoting the GKE service cluster machine type.
- Matchines disk types – The type of persistent disk to be used for the nodes in the Kubernetes cluster, such as SSD, standard storage, or balanced storage.
- Network Private Nodes IP Address – The IP address range assigned to the private nodes in the Kubernetes cluster, representing the GKE service cluster private IP address range.
- Network Name – The name of the network associated with the Kubernetes cluster, specifically the GKE service network name.
- Subnetwork Name – The name of the subnetwork associated with the Kubernetes cluster, denoting the GKE service subnetwork name.
- Network Services Secondary Address Name – The secondary address name for network services in the Kubernetes cluster, representing the GKE service cluster network secondary service address name.
- Network Cluster Secondary Address Name – The secondary address name for the cluster in the Kubernetes network, specifically the GKE service cluster network secondary cluster address name.
- Shared VPC – A boolean value indicating whether the Kubernetes cluster network is on a Shared Virtual Private Cloud (VPC) (True) or not (False).