¶ Data Project Initialization. KubernetesPodOperator (Default) (BigQuery)
DBT Project Name - The name of a dbt project. Must be letters, digits, and underscores only, and cannot start with a digit.
dbt_project.yml
name: 'jaffle_shop_dbt_elt_k8s'
config-version: 2
version: '1.0.0'Project ID - The unique identifier associated with your Google Cloud Project, particularly relevant for BigQuery Data Warehouse.
Airbyte Workspace ID- The identifier for the Airbyte workspace where the data integration pipelines are managed
Source Connection Name- The name assigned to the source connection within Airbyte provides a human-readable label for the connection associated with the DBT project.
Source Connection ID - The unique identifier associated with the specific source connection in the Airbyte workspace, linking the DBT project to a particular data source.
DBT Project Level - The environment or fabric in which the dataset belongs: this is an additional qualifier available on the identifier, to allow disambiguating datasets that live in Production environments from datasets that live in Non-production environments, such as Staging, QA, etc. Default as "Production".
Workload Platform - Specifies the platform used to manage workloads, default "Airflow." Can be Airflow or Composer.
Data Catalog - A boolean value indicating whether data governance (DataHub) features are enabled (True) or not (False).
DBT Data Quality - A boolean value indicating whether dbt data quality (ReDate package) features are enabled (True) or not (False). If DBT_Data_Quality = "true" the orchestration DAG will include a re-data task.
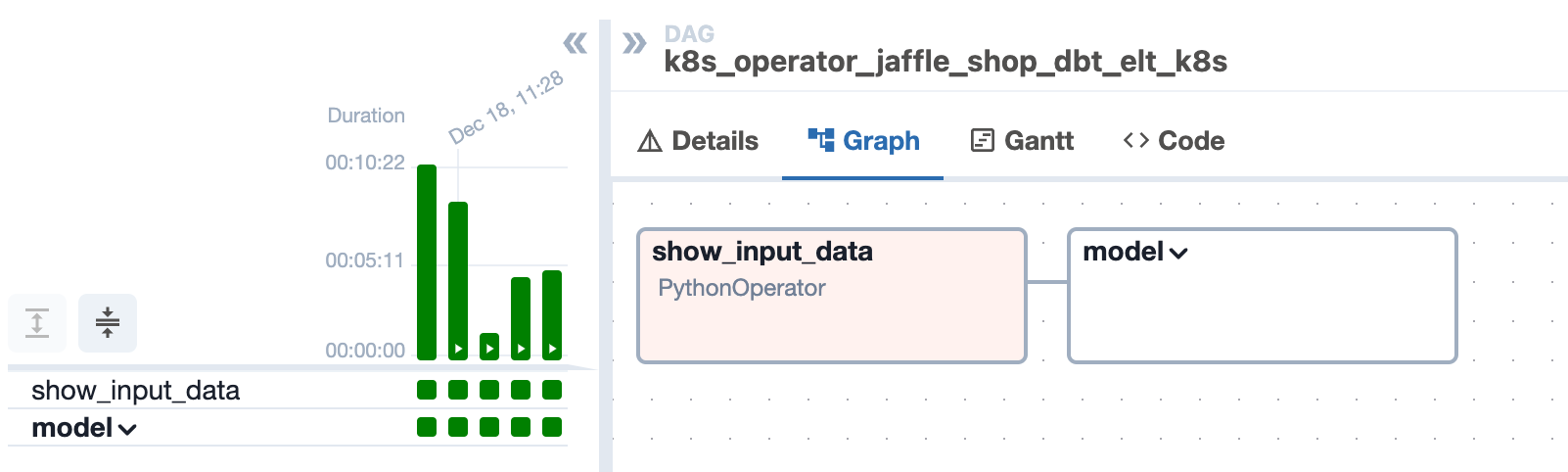
If DBT_Data_Quality = "false" re-data will not work, and you will not see this task in DAG
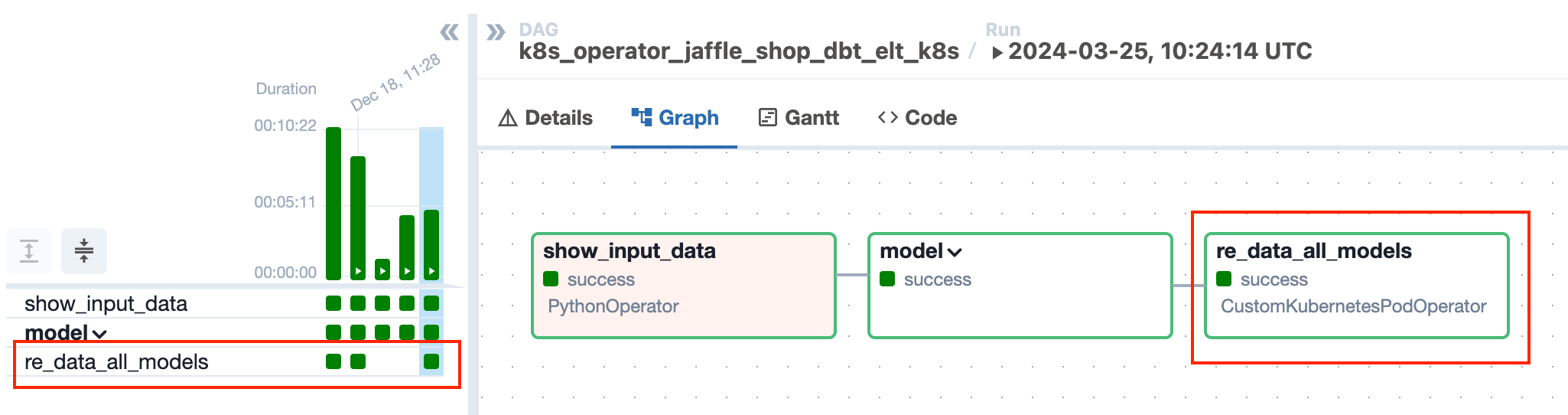
If this task completes successfully (indicated by a green box), it means the re-data tests passed. If any re-data test fails, the task will be marked as failed (indicated by a red box)..
DBT Seed - A boolean value indicating whether dbt seed functionality is enabled (True) or not (False). If DBT_SEED = "true", dbt task for seed files will be created, and in the orchestration DAG will show the seed task group.
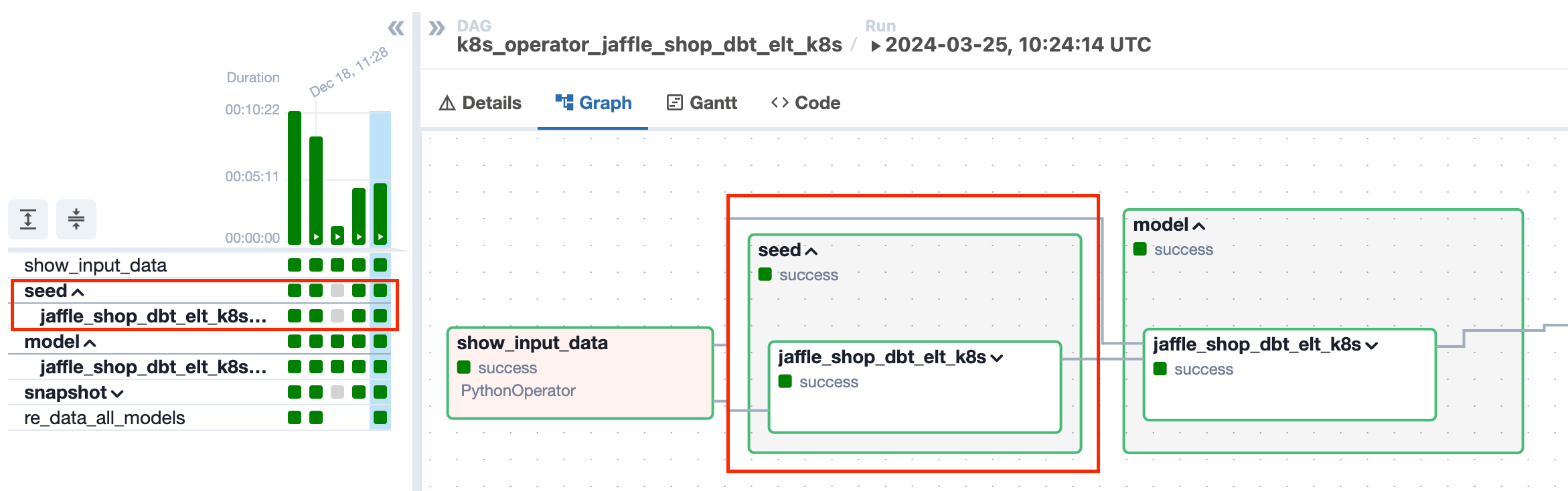
If DBT_SEED ="false" the seed part will be skipped from the pipeline
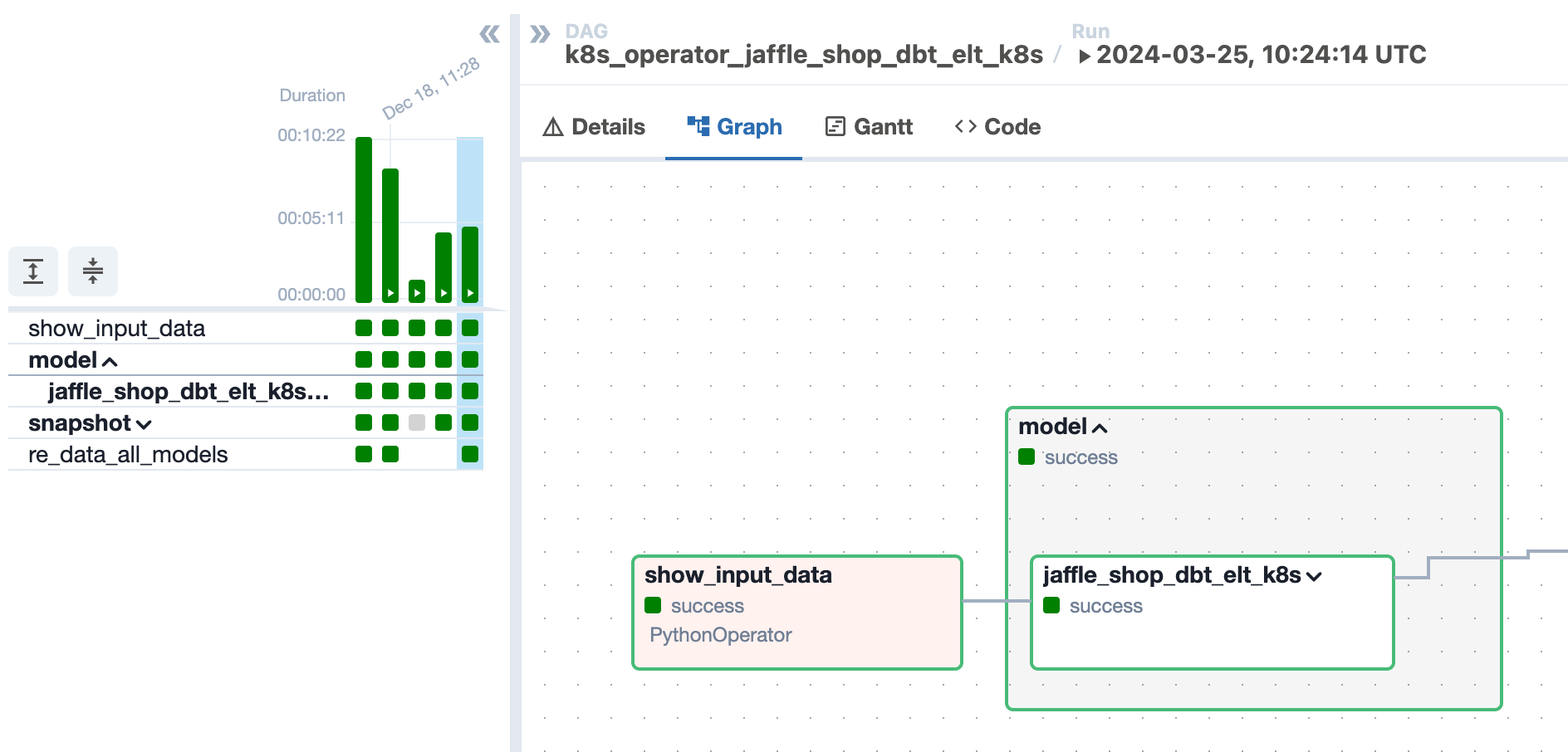
DBT Snapshot - A boolean value indicating whether dbt snapshot functionality is enabled (True) or not (False). If DBT_SNAPSHOT = "true" dbt task for snapshot models will be created.
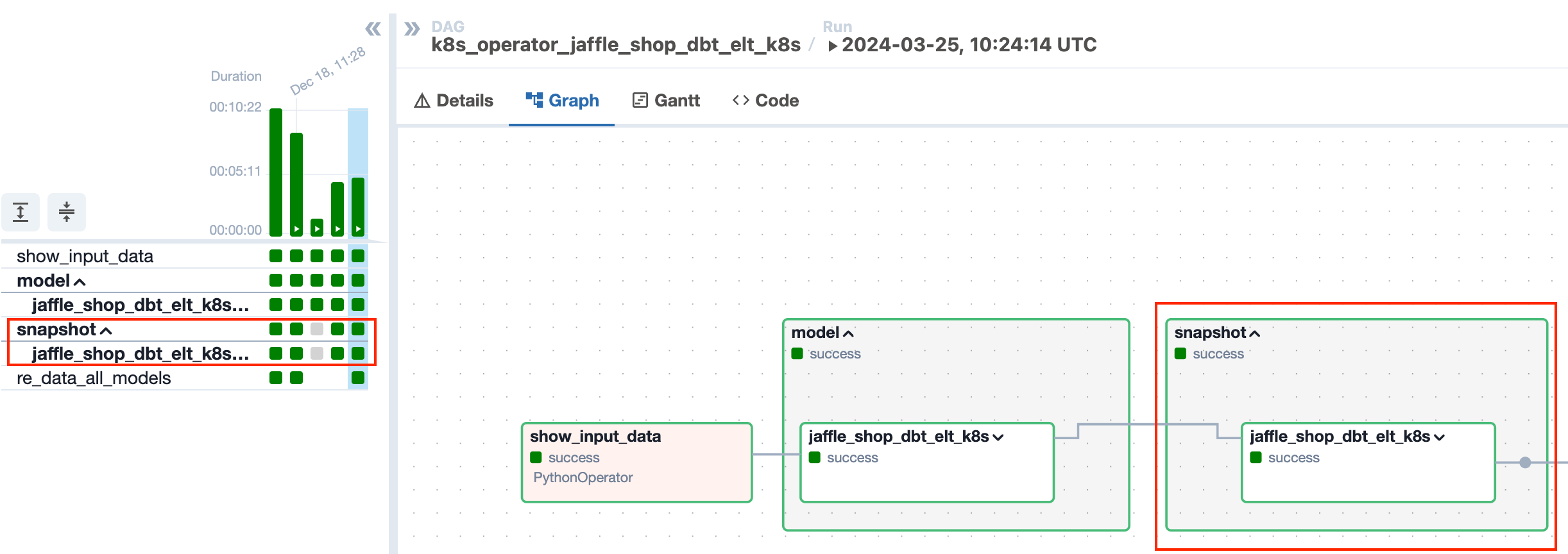
If DBT_SNAPSHOT = "false" snapshot models will be skipped from the pipeline
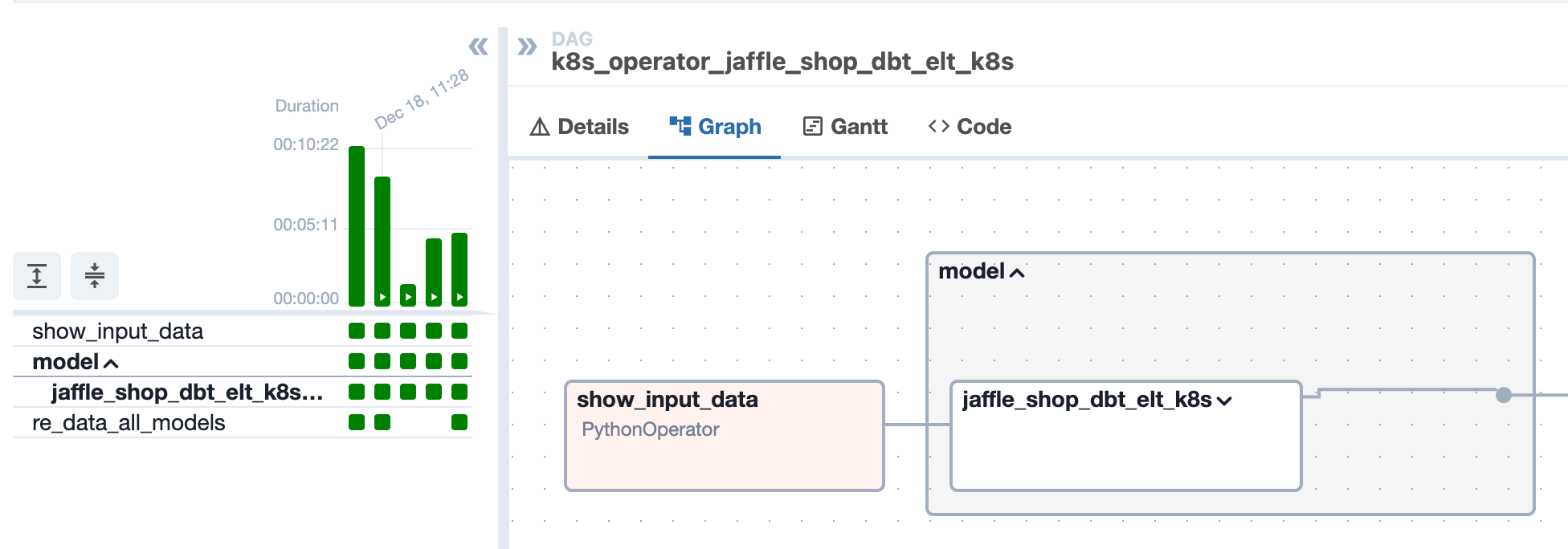
DBT Source - A boolean value indicating whether source tables are displayed in the Airflow UI and the dbt source freshness command is executed. By default set to “true”
DBT Debug - A boolean value indicating whether dbt debug mode is enabled (True) or not (False).
Advanced Properties - A boolean value indicating whether advanced properties (DBT Workload Service Account and Region) are enabled (True) or not (False).
DBT Workload Service Account- The service account associated with the DBT workload specifies the identity used to authenticate and authorize access to resources within the chosen environment.DBT Workload Region- The geographical region or location where the DBT workload will be executed, indicating the physical location of the resources and data involved in the project.
Data Model Repository Branch Name - The automatically generated branch name for the data model repository. You have the option to either continue working with this project from your local environment or the data modeling page.
¶ Extra optional parameters
All additional optional parameters can be added to dbt_airflow_variables.yml in the DBT project.
PLATFORM - If the Data Orchestration is Composer, then variable "Composer", if it's Airflow on the k8s cluster, then variable "Airflow"
NAMESPACE - A Namespace in a Kubernetes Cluster provides a mechanism for isolating groups of resources within a single cluster. By default, it can run on the "default" namespace.
OPERATOR - Template Operator name. For this initialization page, the default will be set to k8s.
POD_NAME - Pod is the smallest deployable unit of computing that can be created and managed in Kubernetes. When the Pod Name variable is set, on k8s pod name starts with this attribute. By default, set to dbt-k8s
GIT_URL - Git website where the repo is stored. By default https://gitlab.fast.bi/
DAG_ID - The composer/Airflow DAG name, name will be shown in the orchestration UI. By default create as “k8s_operator_<dbt project name>”
DAG_SCHEDULE_INTERVAL - Defines when DAG should be triggered and scheduled in cron format.

| preset | meaning | cron |
| None | Don’t schedule, use for exclusively “externally triggered” DAGs | |
@once |
Schedule once and only once | |
@continuous |
Run as soon as the previous run finishes | |
@hourly |
Run once an hour at the end of the hour | 0 * * * * |
@daily |
Run once a day at midnight (24:00) | 0 0 * * * |
@weekly |
Run once a week at midnight (24:00) on Sunday | 0 0 * * 0 |
@monthly |
Run once a month at midnight (24:00) of the first day of the month | 0 0 1 * * |
@quarterly |
Run once a quarter at midnight (24:00) on the first day | 0 0 1 */3 * |
@yearly |
Run once a year at midnight (24:00) of January 1 | 0 0 1 1 * |
You can use an online editor for CRON expressions such as Crontab guru
DAG_TAG - Composer/Airflow DAG Tag, when the tag is set on the UI it is possible to filter DAGs by TAG.
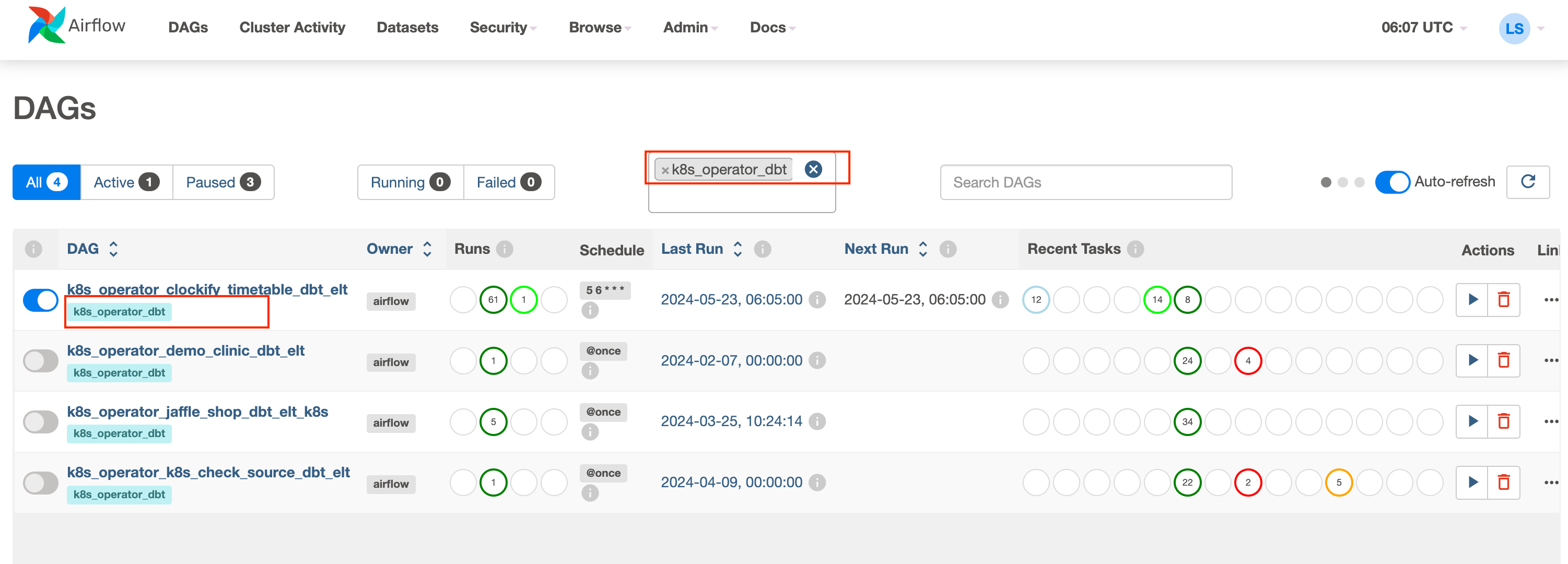
DAG_OWNER - Represents the person, team, or service responsible for the task. By default set to “airflow”.
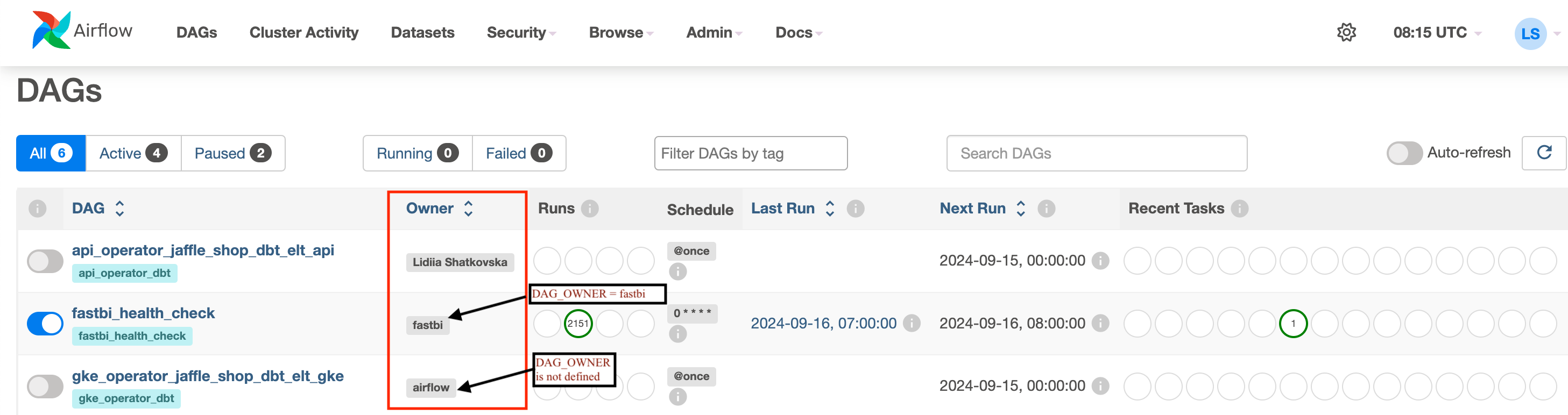
IMAGE - DBT Docker Image for running Data Orchestrator workloads.
DBT_PROJECT_DIRECTORY - Folder Name for DBT project in DBT Repo. The DBT Project will be launched from /data/dbt/dbt-project. By default, set to the same name as the dbt Project Name
MANIFEST_NAME - CI/CD Compiled Manifest file name. When the dbt project in the repo is created or updated, the CI/CD compiles dbt project, creates a manifest file in the dbt target catalogue, and transfers the file into the Composer/Airflow DAGS "main" folder.
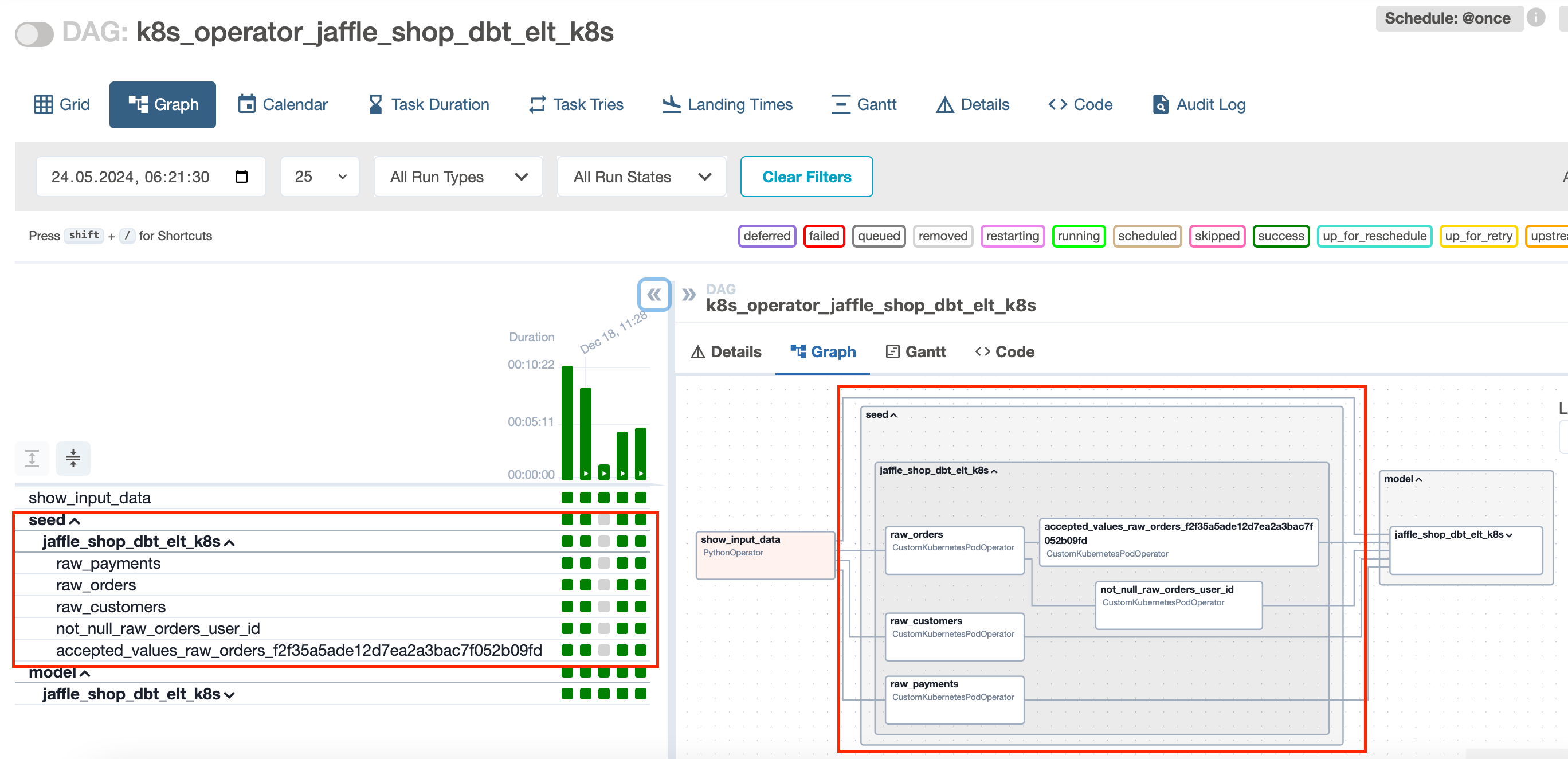
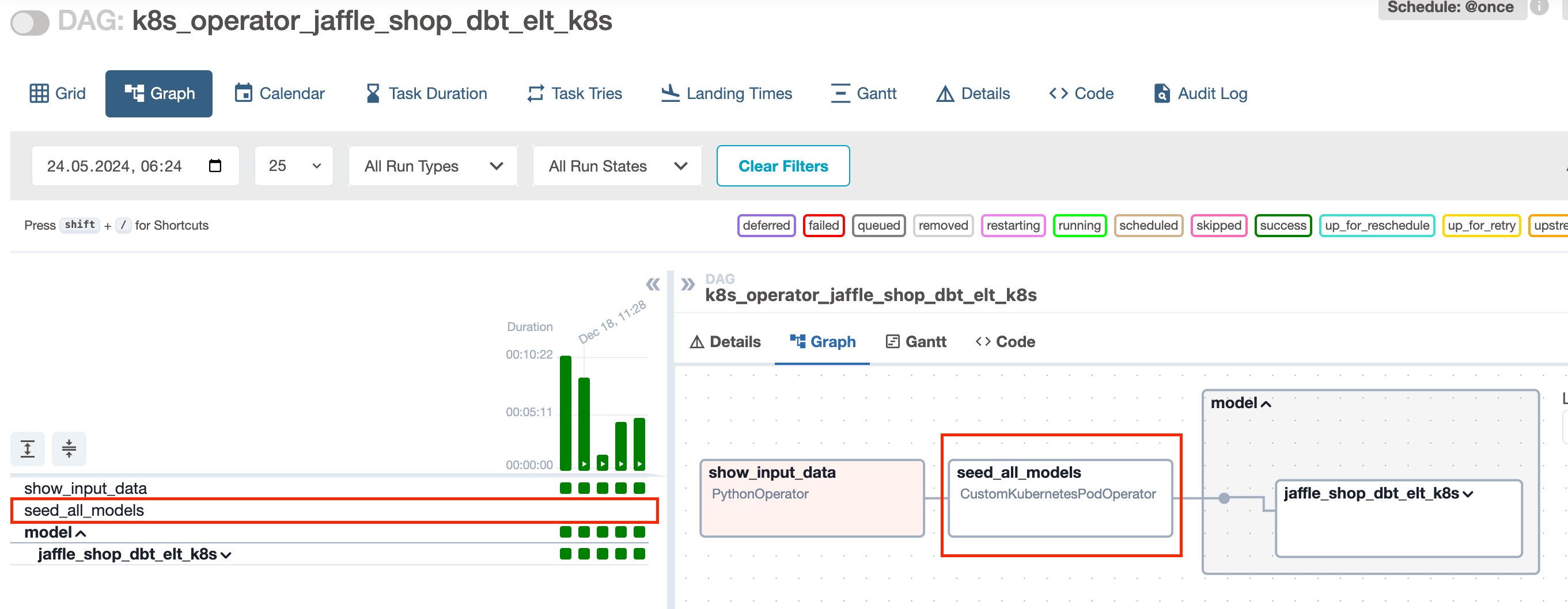
DBT_SEED_SHARDING - True or False, if true, then the seed will be run task by task (file by file).
If DBT_SEED_SHARDING = “true”, then in the background we run the command:
dbt seed --select <file_name>
if DBT_SEED_SHARDING = “false” then run:
dbt seed
DBT_SNAPSHOT_SHARDING - true or false, if true dbt snapshot part is enabled and will run dbt snapshot model by model.
If DBT_SNAPSHOT_SHARDING = “true” then run:
dbt snapshot --select <model_name>
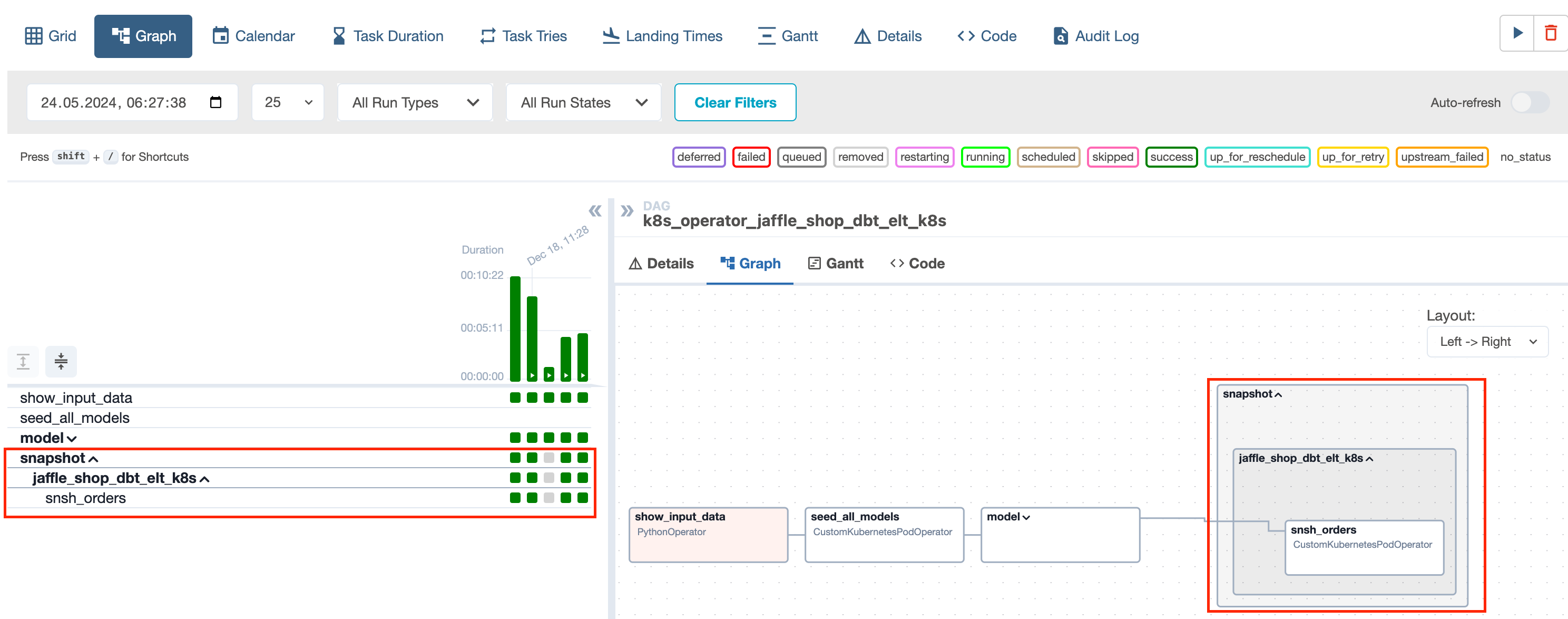
If DBT_SNAPSHOT_SHARDING = “false” then run:
dbt snapshot
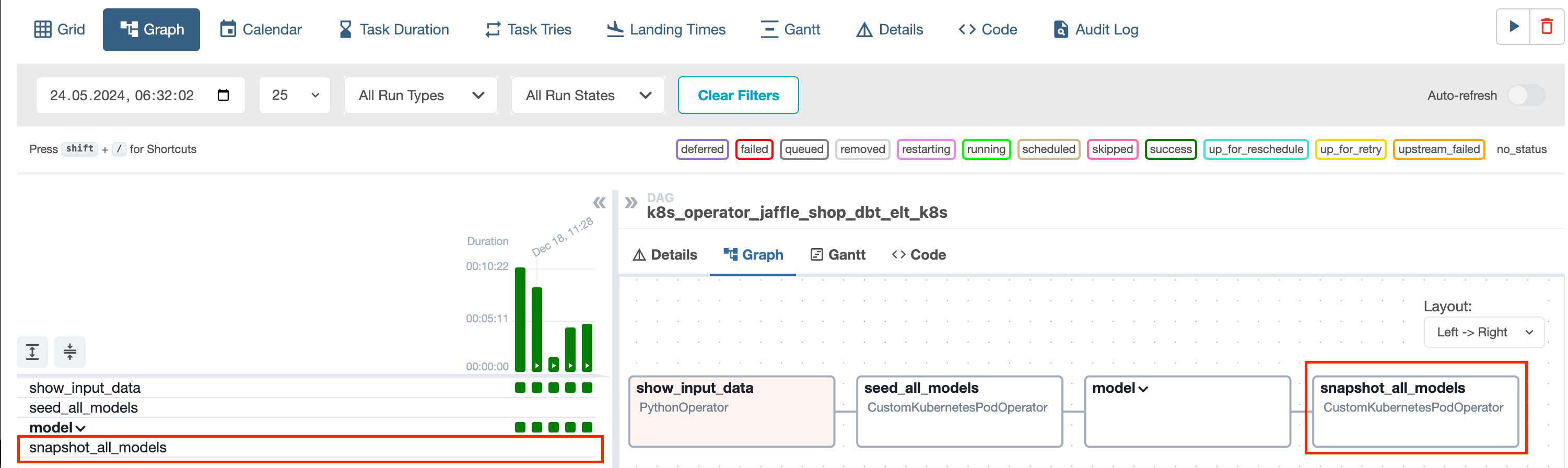
DBT_SOURCE_SHARDING - true or false, if true, the dbt source part is enabled and will run the dbt freshness command source table by table. By default set to “true”
If DBT_SOURCE_SHARDING = “true” then run:
dbt source freshness -s raw_orders
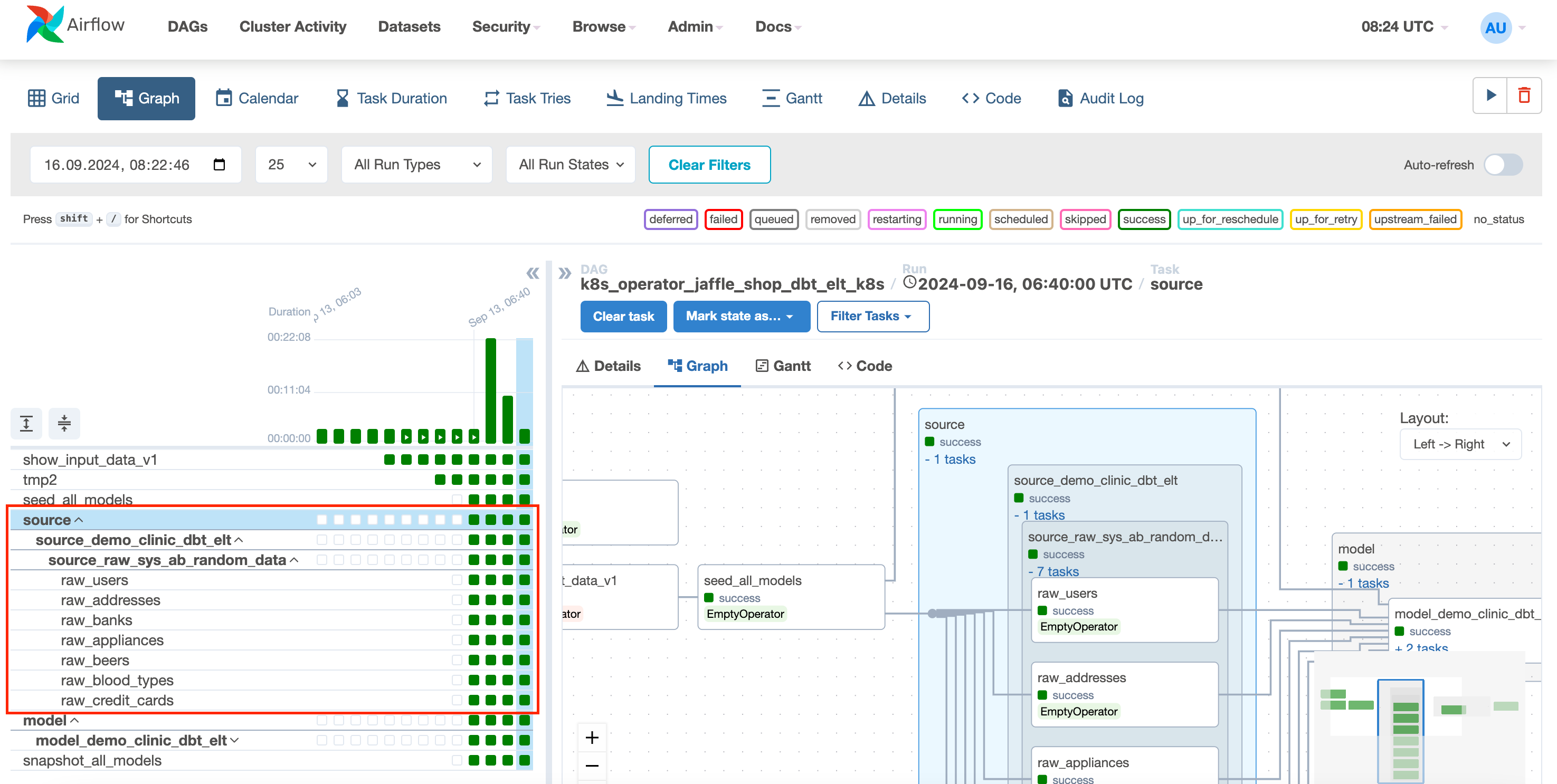
If DBT_SOURCE_SHARDING = “false” then run:
dbt source freshnessMODEL_DEBUG_LOG - If true, the dbt model execution log will be shown in the output log in the Airflow task.
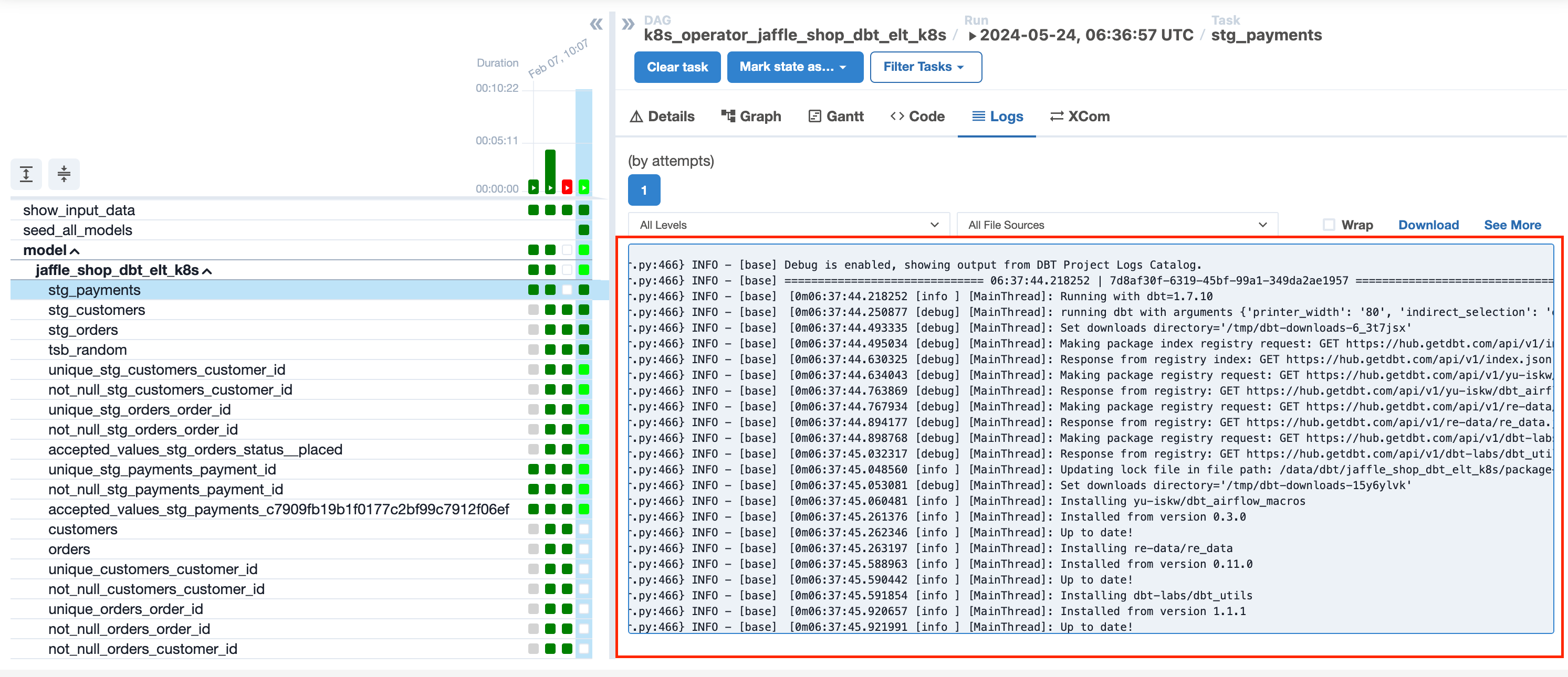
If MODEL_DEBUG_LOG = “true” we can see only general information about the running task
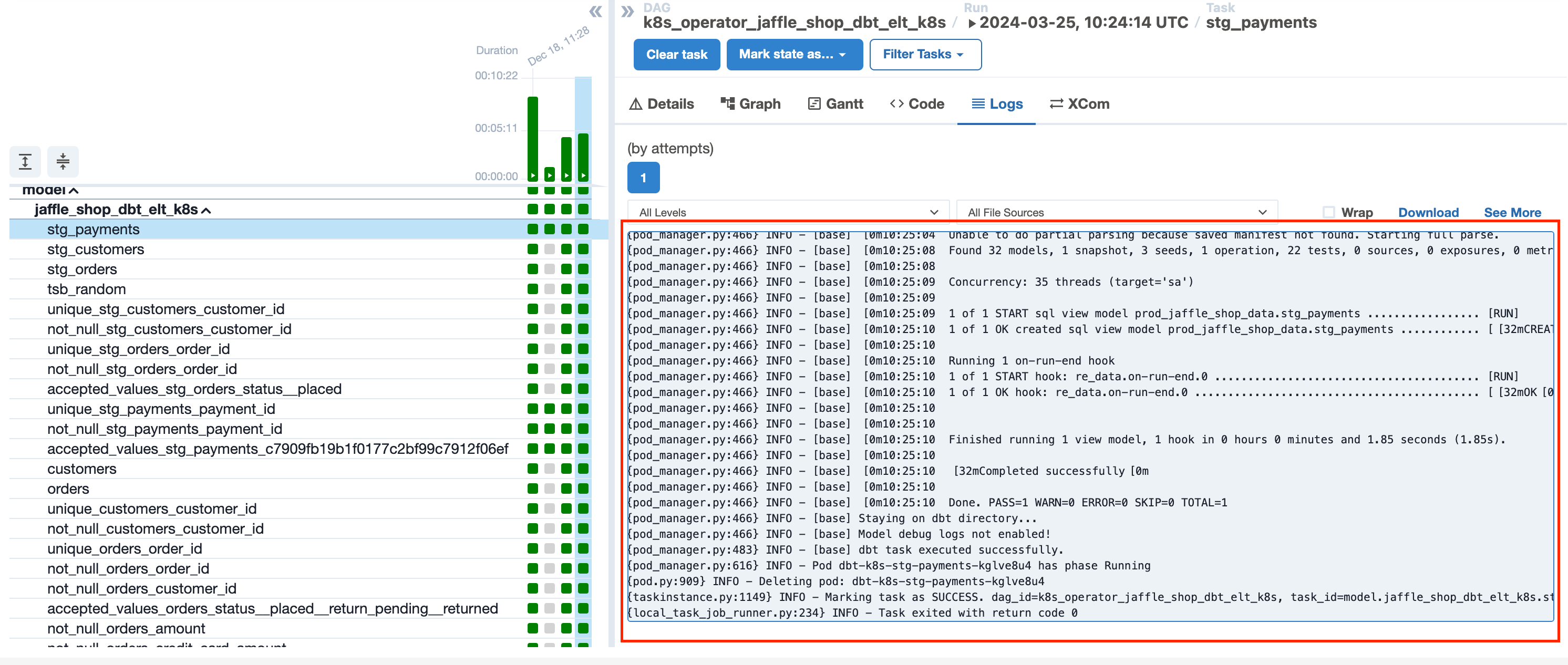
If MODEL_DEBUG_LOG = “false”, we can see additional information, including the executed SQL query, execution time, and a step-by-step flow.
DATAHUB_ENABLED - data catalog parameter. Switch on/off Data Catalog. A data catalog is a detailed inventory of all data assets in an organization, designed to help quickly find the most appropriate data for any analytical or business purpose.
DATA_ANALYSIS_PROJECT - The identifier of the BI project. (For Lightdash use project ID)
AIRBYTE_CONNECTION_ID - The identifier of the Airbyte connection to the source.
AIRBYTE_WORKSPACE_ID - identifier of the Airbyte workspace. The workspace in Airbyte allows to collaborate with other users and manage connections together.