¶ 1. DBT introduction
DBT is an open source platform designed to simplify and streamline the process of transforming data.
DBT features:
- Combine SQL with good software development practices: This enables analysts and data scientists to create dependable, modular code for data transformation, thereby circumventing errors caused by copying and pasting.
- Automate data quality testing: dbt facilitates the establishment of unit and integration tests, ensuring the quality and consistency of transformed data.
- Automatically documents data lineage: This feature simplifies the comprehension of data origins, transformations, and utilization, thereby enhancing transparency and auditability.
- Allows versioning and deployment of data transformation code: This simplifies the execution of modifications, version control, and collaboration among teams, utilizing platforms such as GitHub, GitLab, Bitbucket, or similar services.
Once all required information has been added to the Data Project Initialization page, a fundamental DBT project will be generated in GitHub, GitLab, Bitbucket, or analogous services.
¶ 2. Explore project structure
Fundamental DBT project contains few main components:
¶ Profile.yml
The profile your dbt project should use to connect to your data warehouse
Each profile in profiles.yml can contain multiple targets, which represent different environments (e.g., development, production). A target includes the type of data warehouse, connection credentials, and dbt-specific configurations:
jaffle_shop:
target: dev
outputs:
dev:
type: postgres
host: localhost
user: alice
password: 'password'
port: 5432
dbname: jaffle_shop
schema: dbt_alice
threads: 4¶ To customize profile, update the following information:
Profile name: Replace the name of the profile with a sensible name – it’s often a good idea to use the name of your organization. Make sure that this is the same name as the profile indicated in your dbt_project.yml file.
- target: This is the default target your dbt project will use. It must be one of the targets you define in your profile. Commonly it is set to dev.
- Populating your target:
- type: The type of data warehouse you are connecting to
- Warehouse credentials: Get these from your database administrator if you don’t already have them. Remember that user credentials are very sensitive information that should not be shared.
- schema: The default schema that dbt will build objects in.
- threads: The number of threads the dbt project will run on.
After configuring your profile, use the dbt debug command to validate the connection. This step ensures that dbt can successfully communicate with your data warehouse before proceeding with further operations.
More detail information you can find in DBT documentation: https://docs.getdbt.com/docs/core/connect-data-platform/connection-profiles#connecting-to-your-warehouse-using-the-command-line
¶ dbt_project.yml
The dbt_project.yml file provides essential information to dbt regarding project's structure and the location of resources for future reference. However, additional configuration options are available within this file, allowing you to specify or override dbt's default run settings.
name: demo_clinic_dbt_elt
version: 1.0.0
config-version: 2
profile: demo_clinic_dbt_elt
model-paths: [models]
analysis-paths: [analyses]
test-paths: [tests]
seed-paths: [seeds]
macro-paths: [macros]
snapshot-paths: [snapshots]
models:
demo_clinic_dbt_elt:
# Config indicated by + and applies to all files under models/example/
example:
+materialized: view
+schema: demo_clinic_dbt_elt
vars:
execution_date: '2022-02-02'
data_interval_start: '{{ data_interval_start }}'
data_interval_end: '{{ data_interval_end }}'
source_dataset_name: raw_sys_ab_random_dataname The name of a dbt project. Must be letters, digits and underscores only, and cannot start with a digit.
profileThis setting configures which "profile" dbt uses for this project to connect to WH.
model-paths, analysis-paths, test-paths, seed-paths, macro-paths, snapshot-paths. These configurations specify where dbt should look for different types of files. The model-paths config, for example, states that models in this project can be found in the models/ directory.
models block config tells dbt to build all models in the example/ directory as views. WH dataset defined in the schema parameters will be created. These settings can be overridden in the individual model files using the {{ config(...) }} macro.
vars block. Variables can be passed from your dbt_project.yml file into models during compilation. These variables are useful for configuring packages for deployment in multiple environments, or defining values that should be used across multiple models within a package.
Additional attributes for the dbt_project.yml file can be found in the DBT documentation: https://docs.getdbt.com/reference/dbt_project.yml
¶ Analyses
Analyses directory is used for storing ad-hoc SQL queries or analyses that aren't part of the main data transformation logic. These queries are often used for exploratory analysis or one-time investigations.
¶ Macros
Macros directory is where you can store SQL files that define reusable snippets of SQL code called macros. Macros can be used to encapsulate commonly used SQL patterns, making your code more modular and easier to maintain.
In our DBT project we use macros generate_columns_from_airbyte_yml. This macro uses to unflatten nested json columns in source table to separate columns. It iterates through each model from graph.nodes and apply method JSON_EXTRACT_SCALAR or JSON_EXTRACT_ARRAY for each nested JSON key. Additionally, it verifies the data type and converts it to the correct format if necessary. Another idea of this macros to add incremental logic to our flow. It means that the first time a model is run, the table is built by transforming all rows of source data. On subsequent runs, dbt transforms only the rows in your source data that you tell dbt to filter for, inserting them into the target table which is the table that has already been built.
¶ Models
Models directory is one of the most important directories in a dbt project. It's where you define your dbt models, which are SQL files containing the logic for transforming and shaping your data. Models are the core building blocks of a dbt project.
Dig into how we structure the files, folders, and models for our three primary layers in the models directory, which build on each other:
- Staging — creating our atoms, our initial modular building blocks, from source data. This is the foundation of our project, where we consolidate all the individual components necessary for build our more complex and useful models into the project.
- Intermediate — stacking layers of logic with clear and specific purposes to prepare our staging models to join into the entities we want.
- Marts — this is the layer where everything comes together and we start to arrange all of our atoms (staging models) and molecules (intermediate models) into full-fledged cells that have identity and purpose.
- source.yml — description of all source tables within the WH.
¶ Staging layer
This folder contains list of <source_table_name>.sql files and <source_table_name>.yml.
¶ <source_table_name>.sql
In this file we invoke macros generate_columns_from_airbyte_yml to unflatten nested JSON column data generated from Airbyte.
{{ config(
materialized="incremental",
partition_by={
"field": "execution_date",
"data_type": "date",
"granularity": "month"
},
re_data_time_filter="execution_date",
incremental_strategy="merge",
unique_key=["unique_id"]
) }}
{%- if execute -%}
{{ generate_columns_from_airbyte_yml(source_dataset = "source_dataset_name",
source_table = "_airbyte_raw_addresses",
model_name = "raw_addresses",
unique_key = "id, uid, zip, city, state") }}
{% endif %}Block {{config}} exists to handle end-user configuration for custom materializations.
materialized - materializations define how the model will be materialized into WH.
incremental_strategy="merge" Match records based on a unique_key; update old records, insert new ones. (If no unique_key is specified, all new data is inserted, similar to append.)
unique_key tuple of column names that uniquely identify rows. A unique_key enables updating existing rows instead of just appending new rows. If new data arrives for an existing unique_key, that new data can replace the current data instead of being appended to the table. If a duplicate row arrives, it can be ignored.
partition_by Partition the created table by the specified columns. A directory is created for each partition. When using a datetime or timestamp column to partition data, you can create partitions with a granularity of hour, day, month, or year. A date column supports granularity of day, month and year. Daily partitioning is the default for all column types.
re_data_time_filter re-data (Data Quality) component uses to filter records of the table to a specific time range. It can be set to null if you wish to compute metrics on the whole table. This expression will be compared to re_data:time_window_start and re_data:time_window_end vars during the run.
¶ <source_table_name>.yml
File where models properties can be declared.
version: 2
models:
- name: stg_addresses
columns:
- name: id
identifier: id
data_type: numeric
description: ''
tests:
- unique
- not_null
- name: uid
identifier: uid
data_type: string
description: ''
- name: zip
identifier: zip_code
data_type: string
description: ''
- name: city
identifier: city
data_type: string
description: ''models_name The name of the model you are declaring properties for. Must match the filename of a model.
Columns are not resources in and of themselves. Instead, they are child properties of another resource type. They can define sub-properties that are similar to properties defined at the resource level:
columns_name The column name of the model. Required field.
identifier The table/column name as stored in the WH. This parameter is useful if you want to use a source table/column name that differs from the table/column name in the database.
data_type Specify the data type for the column.
description A user-defined description. These descriptions are used in the documentation website rendered by dbt.
The data tests property contains a list of generic tests, referenced by name, which can include the four built-in generic tests available in dbt. For example, you can add tests that ensure a column contains no duplicates and zero null values. Any arguments or configurations passed to those tests should be nested below the test name.
¶ source.yml
File containing descriptions of all sources in WH that will be used in the models.
version: 2
sources:
- name: raw_sys_ab_random_data
database: fast-bi-terasky
tables:
- name: raw_users
identifier: _airbyte_raw_users
description: ''
columns:
- name: _airbyte_ab_id
description: Transaction ID
data_type: string
- name: _airbyte_emitted_at
description: Transaction Import Time
data_type: timestamp
- name: _airbyte_data
description: Transaction Data
data_type: string
name Name of source table in WH.
databaseThe database that source is stored in.
tables block includes all tables existing in the database.
tables.name The table name intended for use within the models.
tables.identifierThe table name as stored in the database. This parameter is useful if you want to use a source table name that differs from the table name in the database.
descriptionA user-defined description.
tables.columns block includes description, data_type of all columns existing in the table. Additionally, you can include a test for the column.
All of our tables contain the following columns:
_airbyte_ab_id uuid value assigned by Airbyte connectors to each row of the data written in the destination.
_airbyte_emitted_at time at which the record was emitted and recorded by destination connector.
_airbyte_data data stored as a Json Blob
All source parameters describe in DBT documentation: https://docs.getdbt.com/reference/source-properties
¶ Source freshness. Specify Freshness Criteria
Freshness of source tables refers to how up-to-date your data is. It’s an important measure of data quality because it lets you know whether data has been ingested, transformed, or orchestrated on the schedule that you expect.
dbt source freshness is a dbt command to test whether source tables have been updated within a desired frequency. Dbt source freshness tests work are configured using a field loaded_at_field. This is a timestamp column using to check freshness. Dbt looks at this timestamp column in source table and compares it to a time cadence that was set in the parameters. You can choose a time period of minute, hour, day, etc. and specify the numeric quantity. If data is older than the time the test is run minus that cadence, the test will either fail or warn you.
A freshness and loaded_at_field property can be added to a source level, then these block will be applied to all tables defined in that source
It’s important to note that if you add a freshness test to an entire source, rather than an individual source table, the loaded_at_field column needs to be the same in every table within that source. You also need to ensure that the freshness time periods would be the same for every table. We donєt recommend this because it’s unlikely that every source table is updated in the same way.
A freshness and loaded_at_field property can be added to a source table, then these block will override any properties applied to the source.
¶ How to add freshness criteria
- Freshness block need to add in source.yml file. Find the table which you want to check on freshness and add next parameters
sources:
- name: raw_users
identifier: _airbyte_raw_users
description: ''
freshness:
warn_after: {count: 12, period: hour}
error_after: {count: 24, period: hour}
loaded_at_field: _airbyte_emitted_at¶ warn_after/error_after
In the freshness block, one or both of warn_after and error_after can be provided. If neither is provided, then dbt will not calculate freshness snapshots for the tables in this source.
An error_after test will fail test if that condition is not met while a warn_after test will simply make you aware that the data doesn’t meet your expectations.
count is required value. A positive integer for the number of periods where a data source is still considered "fresh".
periodis required value. The time period used in the freshness calculation. One of minute, hour or day.
In our example, we've set a warning threshold of 12 hours and an error threshold of 24 hours.
¶ loaded_at_field
If a source has a freshness: block, dbt will attempt to calculate freshness for that source:
- If a
loaded_at_fieldis provided, dbt will calculate freshness via a select query - If a
loaded_at_fieldis not provided, dbt will calculate freshness via warehouse metadata tables when possible
¶ Filtering freshness tests
While this is not necessary, dbt also gives the option to filter the data that freshness tests are being applied to. For this you need to specify a filter block and then the query you wish to filter your data by. This will add this query as a WHERE clause within your compiled SQL when the freshness test is run.
- name: raw_users
identifier: _airbyte_raw_users
description: ''
freshness:
warn_after: {count: 12, period: hour}
error_after: {count: 24, period: hour}
filter: _airbyte_data != ""2. Open dbt_airflow_variables.yml file and set DBT_SOURCE to True and DBT_SOURCE_SHARDINGto True if you want each table to run as a separate task in Airflow.
DBT_SOURCE: 'True'
DBT_SOURCE_SHARDING: 'True'More information about these attributes in doc
3. Push your changes to repository and you will see source task group in DAG and all information about freshness test in log. When source task running the dbt command dbt source freshness -s <table_name> will be applied
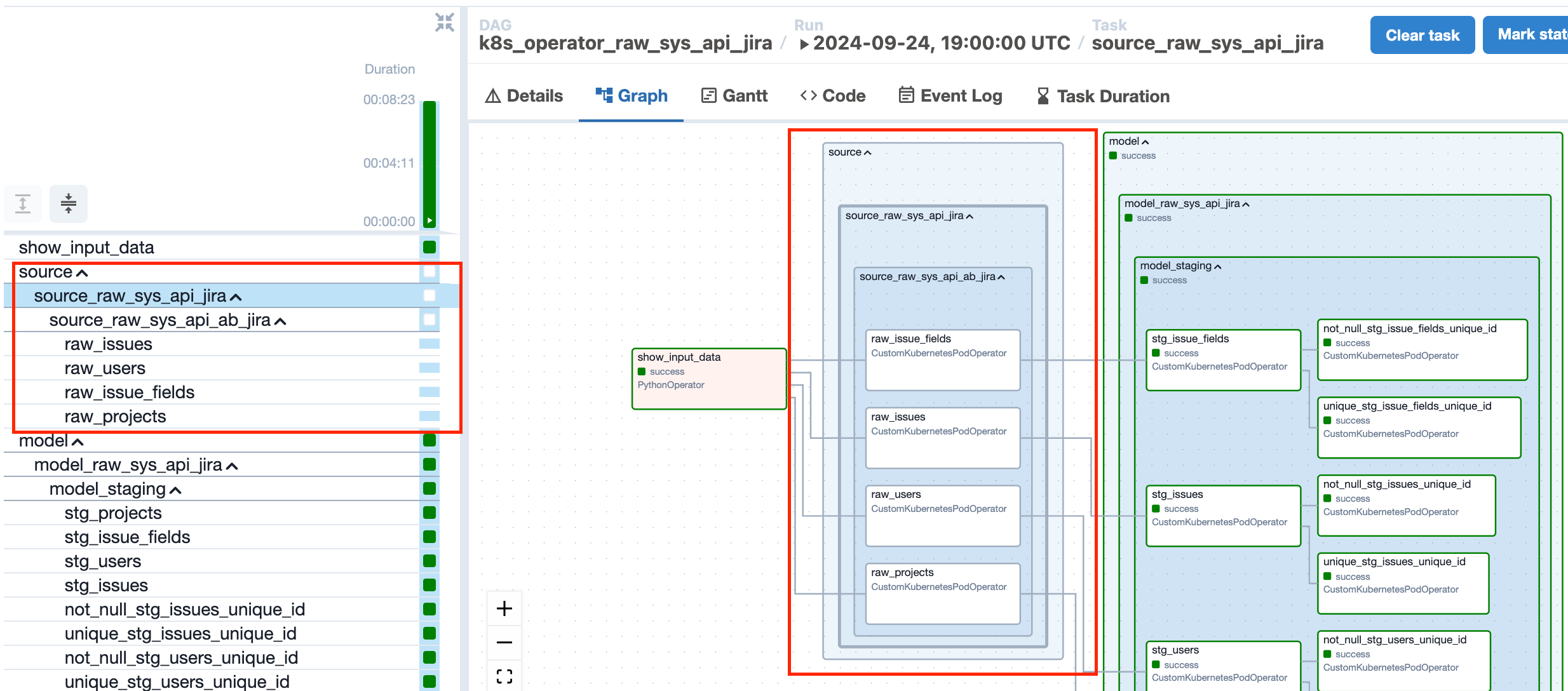
4. For all new dbt projects freshness block with params:
"warn_after": {"count": 24, "period": "hour"},
"error_after": {"count": 36, "period": "hour"}
"loaded_at_field" = _airbyte_emitted_at
will be added to all tables by default. If you don't need them, you can remove freshness block or set freshness: null
¶ Seeds
Seeds directory, is where you can store seed data in a dbt project. Seeds are static datasets that you manually create and manage. Unlike source tables, which dbt typically reads directly from a data warehouse, seeds are user-defined tables that you provide as input to your dbt models.
¶ Snapshots
Snapshots directory is used for creating incremental models or snapshots of the data. Snapshots are useful when you want to capture changes in the data over time.
¶ Tests
Tests directory is where you define tests for your dbt models. Tests help ensure the quality of data transformations by checking for expected outcomes, such as verifying that certain columns are not null or that a column is unique.
¶ README.md
Readme.md file provides an introductory welcome and a list of useful resources.
These directories and files collectively provide a structured environment for developing, testing, and documenting your data transformations using dbt.